




经历过校招死记硬背八股文的朋友们,一定都背过 TCP 的各种名词。类似 慢启动 、拥塞避免、拥塞窗口 、滑动窗口这类概念一定是背了又忘,忘了又背。
本篇,将会结合一次线上下载不满速的情况,对这些概念做一次深入的探索。
当然,对于某些名词可能会假设读者是有所认识,否则若要一一道来,那非得是扒拉着 RFC793 过一遍了。直接进入正题,介绍一下现场(背景)。
故事背景
线上服务多地多节点部署在广州、深圳、天津等城市。服务启动时,会从腾讯云对象存储(COS)拉取文件。文件是统一存放在 广州 地区的存储桶。
观察到的情况是,广深地区拉取文件的速度,相比天津要快上四五倍,见下图。
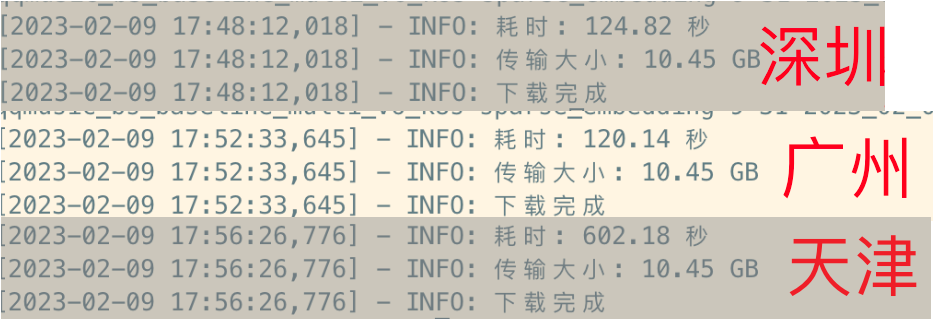
这很不对劲。腾讯云 COS 官网文档上说明,单个存储桶的带宽上限是 15Gbps,不论是哪个节点的速率都远远没有触及存储桶带宽上限。而内网走的都是专线,理论上每个节点的带宽都是一致的。怎么想都不应该唯独天津速度这么慢吧。
节点配额、带宽限速
找到服务容器的宿主机型号,查阅腾讯云后发现,内网带宽限速在 3Gbps。
| 规格 | vCPU | 内存(GB) | 网络收发包(pps)(出+入) | 队列数 | 内网带宽能力(Gbps)(出+入) |
|---|---|---|---|---|---|
| SA2.4XLARGE32 | 16 | 32 | 100万 | 4 | 3.0 |
IPerf3 测速
先排除 COS 的因素,针对天津、广州、深圳三个节点直接测速。
Linux 上,论测速工具,iPerf3 一定独占鳌头。广州的节点模拟 COS 服务,作为 Server,其他两个地区节点分别作为 Client。
可以使用 truncate -s 5G test.file 快速创建一个 5GB 的全 0 文件。
启动 Server 端
# -s 表示启动服务端
# -p 指定启动端口, 默认启动在 5201
# -i 表示日志打印间隔, 单位 (秒)
# -F 指定测速的文件
iperf3 -s -p 5201 -i 0.1 -F test.file
# 最简化的启动
iperf3 -s
Client 端拉取文件开启测速
# -c 表示启动客户端
# -R 表示拉取文件, 而非上传
iperf3 -c [server-ip] -R
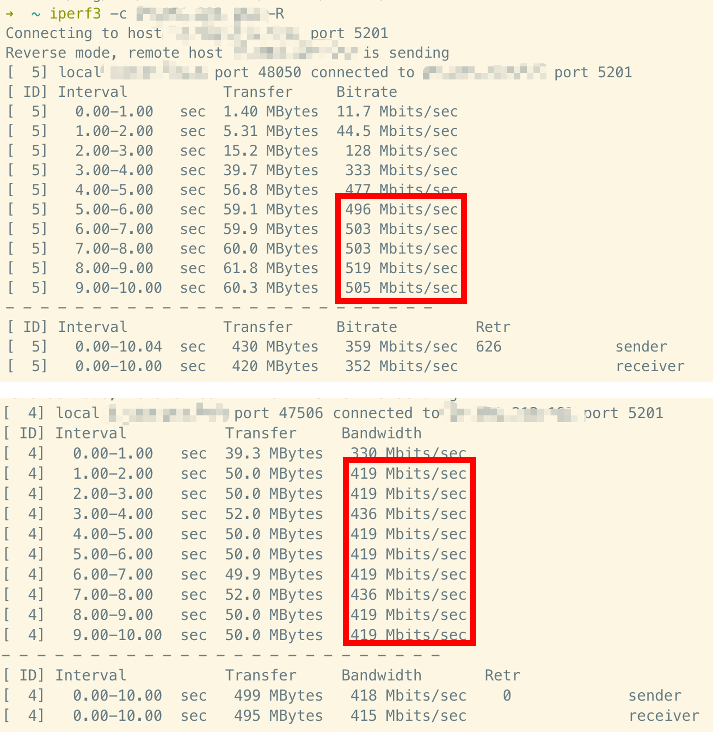
多轮测速下来,结果很是符合预期:
| 地区 | 速率 |
|---|---|
| 广州 → 天津 | 452 Mbps |
| 广州 → 深圳 | 2.95 Gbps |
好家伙,压根儿不在一个数量级了。广深之间倒是跑满了带宽,广州 → 天津存在明显的慢速。
看着这三个地区发了会呆。明明是一样的配置,一样的内网带宽,为什么天津就比广深要慢这么多?这唯一存在的差异,也就是地理因素了吧。乍得一想,莫非是时延?
时延对传输速率的影响
首先看看天津和深圳各自到广州的 ping 值
| 地区 | ping |
|---|---|
| 天津 → 广州 | 35.7 ms |
| 深圳 → 广州 | 3.4 ms |
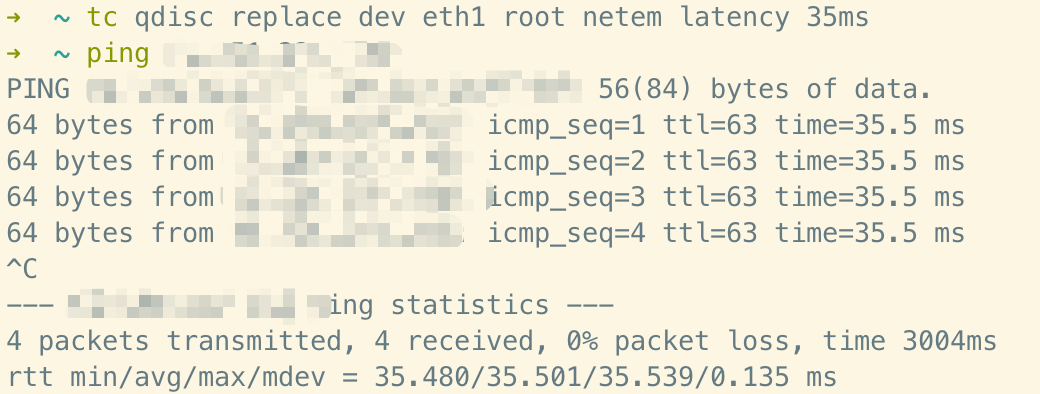
基本 10 倍的时延。根据控制变量法,为了验证时延的影响,将深圳节点的延迟手动调整至与天津一致。这可以通过 tc 命令来实现。
# 为 eth1 网卡添加 35ms 的延迟
tc qdisc replace dev eth1 root netem latency 35ms
# 移除延迟
tc qdisc del dev eth1 root
手动添加延迟完成后,再次 ping 一下。可以看到已经有 35ms 的往返时间了。
接下来,再次测速 广州 → 深圳,并对比之前 广州 → 天津
| 地区 | 速率 |
|---|---|
| 广州 → 天津 | 452 Mbps |
| 广州 → 深圳 | 350 Mbps |
可以发现,广深的传输速率从 2.95 Gbps 降到 350 Mbps 的水平!基本上和 广州 → 天津 差不多。顿时感觉自己找到了结论:高时延会影响传输速率;正准备中场开可乐庆祝下,转念一想,记起了曾经背诵过的 TCP 各个理论,突然又觉得这非常的不合理。
时延真的会影响传输速率吗?
我敢肯定甚至几乎确信,我学过的 TCP 里,时延不会影响传输速率,这是两个维度的概念。
时延和传输速率
首先要明确这两个概念:
-
时延(Latency):从一端主机到另一端主机的总耗时。这个概念受物理因素如光速、两端距离、中间跨过的路由等影响。通常来说,我们可以用 ping 来测试一端到另一端
往返的时延。 -
传输速率(Data transfer rate):通常理解的带宽。表示单位时间内,在数据传输系统设备之间传送比特,字符,或者块的平均值。
我们的下载速度,是和传输速率直接挂钩,和时延没有关系!
时延,只影响了 rtt(Round trip time)。背过的八股文里,rtt 会影响 TCP 三次握手,以及开始传播数据后双边 ACK 的效率。高时延意味着高 rtt,因为一端必须等另一端 SYN 后再 ACK,这是受到 rtt 影响的。
排除了时延带来的影响,意味着我们再次需要找其他的原因了。
其实仔细观察,不论是 广州 → 天津 还是 广州 → 深圳 (高时延),最后的速度都是稳定的。
这很像是被什么因素限速了,因为如果按照正常的 TCP 协议,不论是在指数型增长的 慢启动还是之后各种算法的 拥塞避免、快重传 等阶段,都不会有如此稳定不变的速率。
tcpdump 抓包
唯有抓包,才能彻底分析出这里头的诡异了。在 Linux 上,我们可以使用 tcpdump 来抓取 tcp 包。这里指定 -s 65535 是为了将抓包的日志打包成 wireshark 可以读取的格式,后续导出到办公机上使用 wireshark 做进一步分析。
# -i 指定监听的网卡
# host 指定监听的 域名/ip
# -s 65535 是为了导出 wireshark 支持的格式
# -w 导出到指定文件
sudo tcpdump -i eth1 host [ip] -s 65535 -w gz-tj.log
接下来,再运行一次 广州 → 深圳 和 广州 → 天津 两条链路的 iperf3 测试,这一次用 tcpdump 抓取了 tcp 包并导入到 wireshark 中。需要注意的是,抓包需要在 Server 侧进行。设定 Ip 如下
- 广州 (Server):
10.0.0.1 - 天津 (Client):
10.0.0.2 - 深圳 (Client):
10.0.0.3
就 wireshark 的日志页面简单分析,算是回顾 TCP 的一些理论知识。导入 wireshark 后,会显示完整的 TCP 包传输日志。wireshark 贴心地将 SYN 包置灰,可以看到在 广州 → 天津 的传输过程中,天津 (10.0.0.2) 分别通过 51518 和 51524 端口与 广州 (10.0.0.1:5201) 建立 TCP 连接。
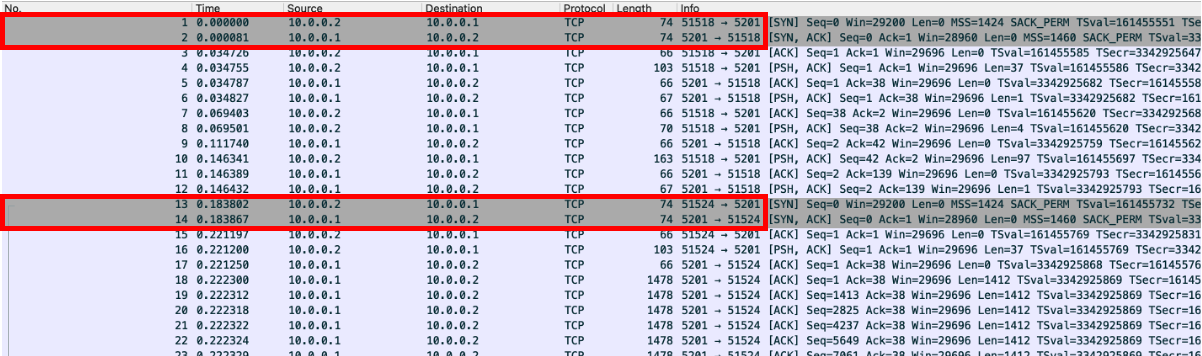
查阅 iperf 的源码后发现,在
iperf_client_api.c#iperf_run_client中,客户端会先后启动ctrl_sck和msg_sck两个socket与 Server 侧的端口建立连接,分别负责控制流和数据流。事实上,FTP 也类似,一个 socket 负责控制流,另一个 socket 负责数据流。
Wireshark 日志分析
数据传输链路的全貌完整展现。简单标注 TCP 的三次握手,数据传送。
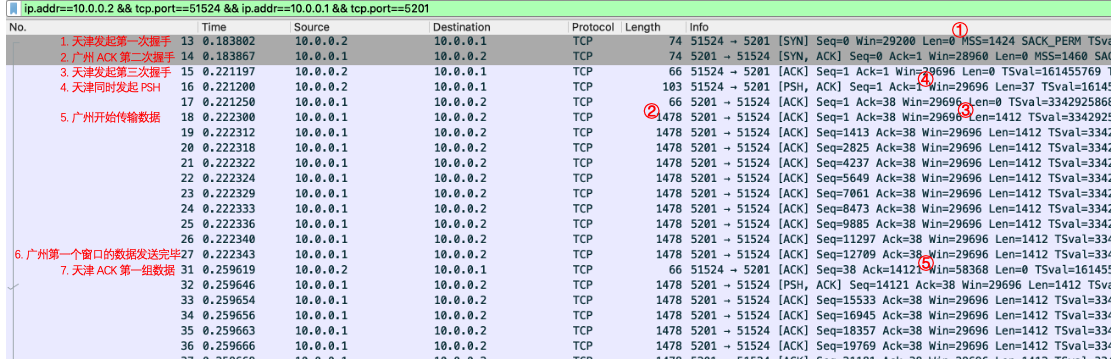
这张图里有许多可以深入研究的地方,我们稍微拓展延伸:
MTU、MSS、Len 和 Length 的关系
- MTU (Maximum Transmission Unit),是链路层允许通过的最大数据包大小,这个值包括了 TCP 包头长度、IP 包头长度 以及 传输数据。可以通过
ifconfig查看网卡的 MTU,一般来说 MTU 都是 1500 Bytes。 - TCP 包头大小。标准 TCP 头大小为 20Bytes。但是按照 RFC793 的规范,TCP 头的
0x20~0x24位是Data Offset表示了该 TCP 头的大小。在我们测试的链路中,Data Offset 是1000,也就是 TCP 头大小为 32Bytes.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window |
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
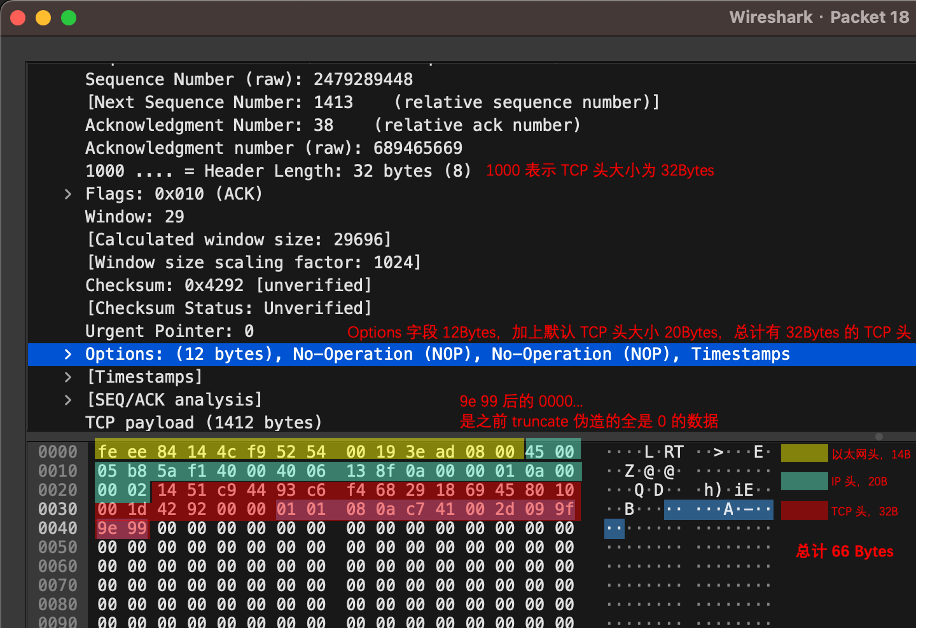
- MSS (Maximum Segment Size),是 TCP 报文中,所能携带最大的载荷大小。按照 ① 指示的 ,其实是根据 计算而来的。
在上图的 TCP 日志中,三次握手中,确定了本次会话的固定 。换句话说,这次会话中,每个 TCP 包最大有效载荷为 1424Bytes。
可是,根据 ③ 来看,实际载荷仅为 1412Bytes,这中间的 12Bytes 上哪去了?
这是因为,TCP 还有一个 Options 字段,它在原来 20Bytes 的基础上,额外占用了 12Bytes 用于存放 Timestamps 等信息。
最终一张图总结 Header。
发送窗口图表分析
跑偏了,我们继续分析慢速的原因。在 wireshark 的菜单栏选择 Statistics → Tcp Stream Graphs → Window Scaling。
图中蓝线表示发送端发送窗口一次发送的包大小,绿线表示接收端的接收窗口大小变化。
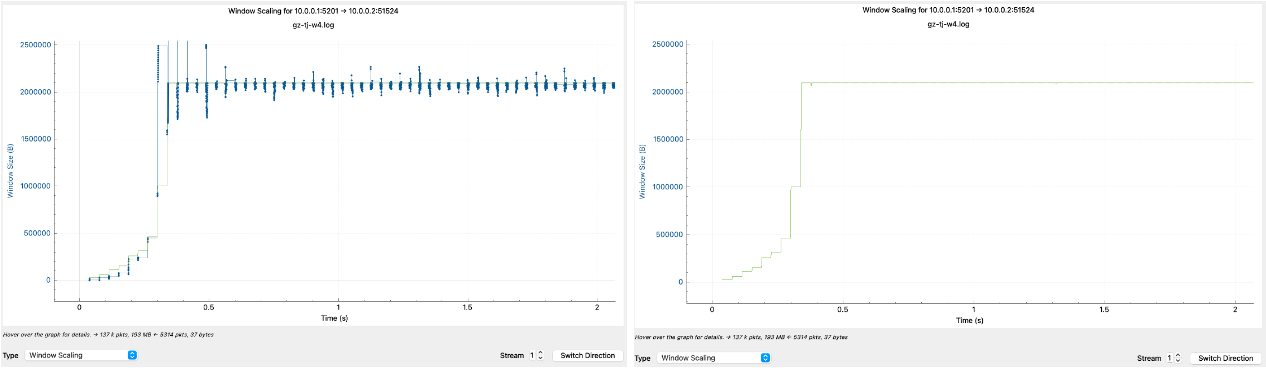
我们可以立即判断出,蓝线,也就是发送窗口,在 0.3 秒之前是符合 慢启动 标准的。它指数型上涨,每波发送间隔大约 35ms(正好是 广州 →天津 的 rtt),并且每隔一个 rtt 后发送窗口涨一倍。
但是在 0.3 秒后,发送窗口大小像是撞到了无形屏障似的,被死死固定在一条横线上。
为什么发送窗口不再增长了?
我想这个问题的答案,肯定是解决限速问题的关键。
发送窗口限制因素
对于发送端来说,有三样东西影响了自己的发送速率:
- 网络链路的传输能力
- 接收端的接收能力
- 发送端的发送能力
其实大半个 TCP 设计规范都在围绕 1 做文章,因为对于一次 TCP 会话,两端都没办法知道当前网络链路质量情况。网络链路质量的不透明,直接催生出 慢启动、拥塞避免、快重传、快恢复 等一系列拥塞控制机制。一言以蔽之,几乎所有的拥塞控制,都是在不断地试探并且逼近网络链路所能承担的吞吐最大值。
想一想为什么慢启动 cwnd 要指数增长,为什么 cwnd 到达 ssthresh 后要触发拥塞避免,为什么发明了各类诸如 RENO,BIC,CUBIC,BBR 等拥塞避免算法。这都是因为 TCP 希望在通信过程时,从复杂且不透明的网络中,一点点将自己的传输能力提升到网络所能承担的最大值。
在广域网的世界里,相比 1 (网络链路能力),2 (接收端接收能力) 和 3 (发送端发送能力) 并不太受到人们的关注,因为 2 & 3 实在是太简单,太稳定,太高效了。在广域网上,一个数据包可能要穿越过五湖四海(过太平洋的确是跨海了),路过数不尽的路由,冒着随时走丢的风险,历经千辛万苦才能来到接收端的门口。而发送端和接收端,仅仅需要与磁盘和内存打交道。
发送端和接收端的送客(揽客)效率,只受到网卡、内存、磁盘速率的影响。这个速度相比于网络链路上的传输速率来说,实在是过于稳定且高效了。正因为此,我们往往忽略了发送端、接收端对于传输速率的影响。
首先说结论,发送窗口的大小取自 。而这次的问题,正是出在接收端 rwnd 上。
- cwnd (Congestion Window),拥塞窗口,诞生于拥塞控制,是发送端为了趋近又不超过网络链路所能。cwnd 受到拥塞算法和发送缓冲区大小的限制。
- rwnd (Receive Window),接收窗口,TCP 包头字段,表明自己的接收缓存大小,即自身还能接收多少数据。这个字段在上面 TCP 日志图中 ④ ,⑤ 有体现。
TCP RcvBuffer
在 Linux 中,TCP rwnd (Receive Window) 与 TCP receive buffer 有关。下图摘自 Computer Networking: Top Down Approach 6th edition。
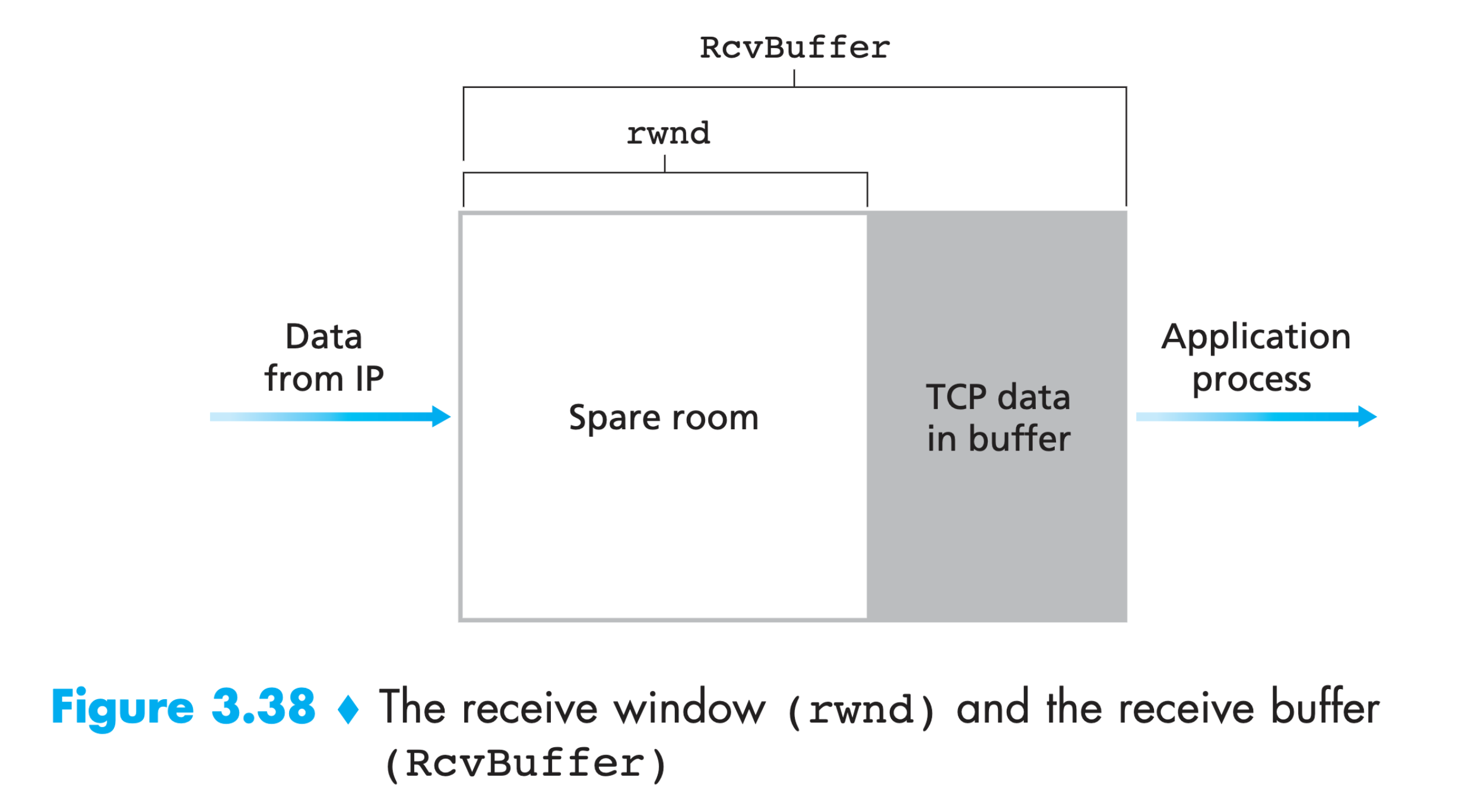
rwnd 其实在每次 TCP 包头中都会传递,也就是 wireshark 日志中标记的 ④ 和 ⑤ ,表示接受方当前剩余的 buffer 空间。
而 TCP receive buffer 受 Linux 内核中的 net.ipv4.tcp_rmem,net.core.rmem_max 和 net.ipv4.tcp_adv_win_scale 三个参数影响。可以通过 sudo sysctl -a | grep "rmem" 来确认这三个参数的值。需要注意,net.ipv4.* 的优先级高于 net.core.*。
从 TCP Linux manual page 中总结这几个参数:
| 参数 | 类型 | 说明 |
|---|---|---|
| tcp_rmem | [min, default, max] | 用来调节接收缓冲区大小,分别表示接收缓冲区的最小、默认和最大值 |
| tcp_moderate_rcvbuf | Boolean | 如果启用,将执行接收缓冲区自动调优,调整后的大小不会比 tcp_rmem[2] 更大;默认启用 |
| tcp_adv_win_scale | Integer | 用于计算 rwnd,见下文;默认为 2 |
| tcp_window_scaling | Boolean | 启用 rfc 1323 TPC 窗口缩放;默认启用 |
| tcp_timestamps | Integer | 0 表示关闭;1 表示开启;开启后会在 TCP 包头多占用 12Bytes,默认 1 |
TCP receive buffer 其实并不直接等于 rwnd,rwnd 有一个计算公式:
在我的服务中,这两个内核参数的值分别为
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_rmem = 8192 87380 4194304
由此可以计算出,默认会话中 。这个值,和发送窗口图表中的绿线最终稳定的值,一样。现在基本可以确定,接收端的内核接收内存大小参数是这次慢速的根本原因。
请确认
net.ipv4.tcp_window_scaling为 1,否则 rwnd 将会被限制在 64KB
Window Scaling
上文说到 rwnd 在不开启 net.ipv4.tcp_window_scaling 的情况下,会被限制在 64KB,那么这个 window scaling 参数是什么东西呢?
通过 TCP 报文规范,包头 Window 字段只有 16 位长度,意味着 Window 大小最大为 。这个 64KB 的窗口大小放在 50 年前 TCP 诞生的时候恰恰好,但是放在带宽(特别是局域网)指数级增长的现在,已经完全不够用了。但是 TCP 的规范不能随意更改,只能另外扩展字段。因此在 RFC 7323 中提出,新增一个 14 位的 Window scaling 的字段,表示接收窗口的放大倍数。至此,接收窗口最大值被放大到 。
再次测速
为了验证 rwnd 对传输速率的影响,我们将 windows size 调大。可以通过 sudo sysctl -w net.ipv4.tcp_rmem="8192 87380 33554432" 将接收 buffer 调大 8 倍;如果是容器环境无法调整,iperf3 同样提供 -w 参数指定 windows size。
温馨提醒,tcp_rmem 和 rwnd 不相等。
iperf3 的 -w 参数是指直接设定 rwnd;
tcp_rmem 需要经过上文的公式计算得到最终的 rwnd
再次运行 广州 → 天津 的测速。

| 地区 | 速率 |
|---|---|
| 广州 → 天津 (rwnd=2MB) | 452 Mbps |
| 广州 → 天津 (rwnd=16MB) | 2.89 Gbps |
对劲儿!速度直接拉满了。再到 wireshark 中看看发送窗口图表。
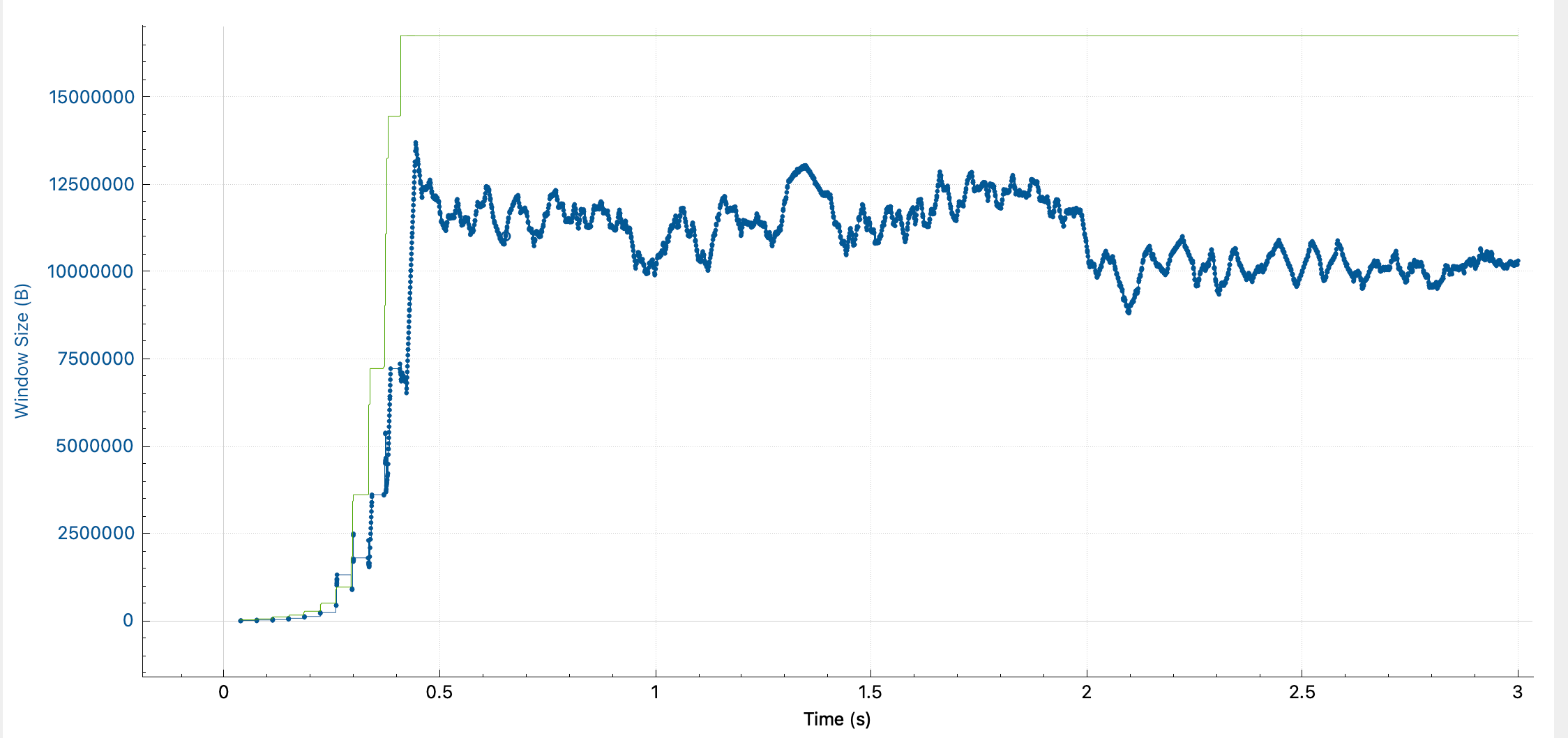
可以看到 rwnd 一路指数上涨到 16MB 后稳定,而发送窗口在慢启动后,终于没有被平稳限制,最终因为带宽限制在 3Gbps 而不断上下波动。慢启动的有非常典型的行为,一个是 cwnd 指数上升,一个是间隔 rtt 后上升。由于 广州 → 天津 有 35ms 的时延,慢启动过程中的等待在图中还是清晰可见的。
其实细心的读者现在肯定有另一个疑问,深圳的节点也同样是 4MB 的接收内存,为什么没有被限速呢?在讨论这个问题前,我们再回过头来看看 时延。
再谈时延——带宽时延积
随着带宽的增长,RFC 很快提出了带宽时延积(BDP, bandwidth-delay product)的概念。BDP 对于长肥网络来说是一个非常重要的概念,长肥网络是指 带宽 (Bandwidth) 与 时延 (Rtt) 乘积很大的网络。一般体现在跨城(海)专线或者卫星通信上,这类网络带宽非常大,同时时延也比较高。
我们假设以下的极端场景,接收端只有缓存 64KB 数据包的 RcvBuffer 大小,接收端与发送端的 RTT 是 1000ms。在 TCP 握手时,发送端就确认了接收端的接收窗口大小为 64KB。因此发送端一次只会发送 64KB 大小的数据包,在这之后发送端需要等待接收端的 ACK 回包,这就需要 1s。因此,整个链路的传输速率被死死限制在了可怜的 64KB/s。
而如果接收端的 RcvBuffer 提升到 64MB,那么这次 TCP 会话的传输速率起码提升了 1000 倍!
一般推荐窗口大小设置为 BDP。在我们的场景中,带宽是 3Gbps,rtt 是 35ms。可以计算出合适的窗口大小为 13MB 左右。
此时回过头来看看深圳的 2MB 接收缓存,在仅仅 3.5ms 的时延下,接收端 ACK 回包的速度很快,发送端能很快感应到并发送数据。

上图截取了发送端在发送 Seq 为 200000000 左右时的交互记录,可以看到 广州 → 深圳中,深圳回 ACK 的 Lag 在 985036Byte 差不多 960KB 左右。也就是说,发送端此刻认为 bytes-on-flight 为 960KB,深圳此刻的接收窗口为 2MB,所以发送端可以立马发送 1MB 的包过去。
反观 广州 → 天津,在 RcvBuffer 为 2MB 时,天津回 ACK 的 Lag 在 2060108Bytes 差不多 1.96MB。发送端此刻认为 bytes-on-flight 为 1.96MB,结合天津此刻的 2MB 接收窗口,发送端只会发送 40KB 的包。
而当 RcvBuffer 设置为 16MB 时,天津回 ACK 的 Lag 虽然有 6.55MB,但是发送端认为除了在路上的这 6.55MB,接收端的 16MB RcvBuffer 还能再收 9.45MB。所以立马,发送端会发送 9.45MB 的数据。
解决方案
分析这么一大通,根本原因在于接收缓冲区的大小设置过小,所以根据带宽调整缓冲区的大小即可。
这时候有的同学就要问了,如果容器环境,没有 privileged 权限,无法调整内核参数怎么办呢?
其实,接收缓冲区是 Socket 的概念,也就是对一次 TCP 会话生效。既然在一次 TCP 连接中因为接收缓冲区的大小导致限速,那么启动多个 Socket 连接就好了嘛。换句话说,用多线程结合 HTTP 的 Range 属性,分 Range 同时下载,这可是最简单的提速方式了。
总结
在网络链路简单纯粹的内网环境中,丢包重传的概率是很低的,因此大部分情况下都还没到拥塞避免的阶段。出现网络异常的问题,可以优先从链路双端开始排查。
本文主要讨论了接收端窗口设置过小时延过大的情况;而当发送端窗口过小时,又会发生什么呢,这个就留给读者们思考探索一下了。
当然,如果涉及到丢包启动拥塞避免算法,这又是另外一个长篇才能解决的问题了。
评论区